Vector Search and Vector Database Algorithms: A Comprehensive Overview
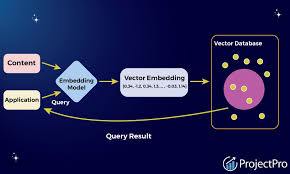
As the digital landscape continues to evolve, the demand for efficient and precise data retrieval has become paramount. In response to this need, vector search technology and vector databases have emerged as powerful tools, revolutionizing the way we interact with and extract information from vast datasets. In this article, we will provide a comprehensive overview of vector search and the algorithms that drive vector databases, shedding light on their significance in modern data management.
Table of Contents
Understanding Vector Search Technology
What is Vector Search?
Vector search involves the use of mathematical vectors to represent and compare items in a dataset. Unlike traditional search methods that rely on keywords or exact matches, vector search takes advantage of vector representations to measure the similarity between items. This approach enables more nuanced and context-aware search results.
How Vector Search Works
- Vector Representation: Each item in the dataset is represented as a vector in a multi-dimensional space. The dimensions of the vector correspond to different features or attributes of the item.
- Similarity Measurement: The similarity between vectors is measured using mathematical metrics such as cosine similarity or Euclidean distance. This allows for the identification of items that are close in the vector space, indicating a high degree of similarity.
- Efficient Retrieval: Vector search algorithms enable efficient retrieval of items based on their similarity, making it particularly effective for applications like recommendation systems, image recognition, and natural language processing.
The Algorithms Behind Vector Search
1. Cosine Similarity
- Definition: Cosine similarity measures the cosine of the angle between two vectors. It ranges from -1 (completely dissimilar) to 1 (identical). A lower angle indicates a higher similarity.
- Application: Widely used in natural language processing for document similarity and recommendation systems.
2. Euclidean Distance
- Definition: Euclidean distance measures the straight-line distance between two points in a multi-dimensional space. Smaller distances indicate greater similarity.
- Application: Commonly applied in image recognition and clustering algorithms.
3. Jaccard Similarity
- Definition: Jaccard similarity measures the intersection over the union of two sets. It is often used for comparing sets of items.
- Application: Valuable in applications where the presence or absence of specific features is crucial, such as in DNA sequence analysis.
4. Hamming Distance
- Definition: Hamming distance measures the number of positions at which corresponding bits differ in two binary strings.
- Application: Frequently utilized in error detection and correction algorithms.
Advantages of Vector Databases
Vector database, built on the principles of vector search, offer several advantages over traditional databases:
- Efficient Handling of High-Dimensional Data: Vector databases excel in managing data with numerous dimensions, making them suitable for applications like image and video processing.
- Scalability: These databases are designed to scale horizontally, ensuring optimal performance even as the volume of data increases.
- Real-time Processing: Vector databases enable real-time data retrieval and analysis, crucial for applications such as financial trading and live event monitoring.
Challenges and Solutions in Implementing Vector Search
Challenges:
- High Computational Costs: Calculating similarity scores for large datasets can be computationally intensive.
- Data Quality and Noise: The effectiveness of vector search relies on the quality of vector representations, and noisy data can impact accuracy.
Solutions:
- Parallel Processing: Distributing computations across multiple processors can significantly reduce computational costs.
- Data Preprocessing: Cleaning and preprocessing data before vectorization enhance the quality of vector representations.
Future Trends in Vector Search and Database Technologies
As technology advances, several trends are shaping the future of vector search and database technologies:
- Embedding Learning: The integration of embedding learning techniques is enhancing the ability of vector search to capture complex relationships within data.
- Hybrid Approaches: Combining vector search with other indexing methods to create hybrid systems for improved performance and accuracy.
- Edge Computing Integration: The integration of vector databases with edge computing for faster and more efficient data retrieval in decentralized environments.
Conclusion
In conclusion, the evolution of vector search technology and the algorithms powering vector databases have significantly influenced the landscape of modern data management. As organizations strive for faster and more precise data retrieval, the role of vector search becomes increasingly crucial. Understanding the underlying algorithms and their applications empowers businesses to harness the full potential of these technologies.
Whether applied in recommendation systems, image recognition, or other data-intensive tasks, vector search and databases are at the forefront of innovation, enabling a new era of efficiency and accuracy in information retrieval.
For further exploration of vector database solutions and their applications, visit DataStax.com – your gateway to cutting-edge data management technologies.






